![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
134 Cards in this Set
- Front
- Back
|
TCP IP layers |
Application Transport Network Link Physical |
|
|
What does the link layer do? 4 points |
Shields upper layers from specific connection type. Transmits frames over physical media + encapsulates ip datagrams into frames Receives frames and passes ip datagrams up the stack Detects and handles transmission errors l |
|
|
What is a frame |
A packet, header, and trailer |
|
|
3 characteristics of distsys |
Concurrency No global clock Independent features |
|
|
What is a data frame |
Frames that vary based on the physical layer e.g. ethernet frame |
|
|
Describe flow control |
Regulating the flow of data so a slow receiver is not swamped by a fast sender |
|
|
Describe the three options for link layer acknowledgements |
Conectionless and no acknowledgement (Low error rate networks e.g. wired ethernet. Connectionless means no signal path decided in advance)
Acknowledged Connectionless (WiFi)
Acknowledged Connection oriented (Long delay, unreliable links e.g. satellite) |
|
|
Describe the stop and wait automatically repeated request (ARQ) |
A way to handle acks and errors. Sends a frame then waits for ack then sends next frame etc.
Can be improved by pipelining. Send multiple frames before receiving first ack |
|
|
Describe go back N ARQ |
Uses a sequence of numbers to lable each frame. Sends many frames then if an ack is missed re send everything from that frame onwards |
|
|
Describe selective repeat ARQ |
Similar to go back N ARQ but only resend the missed frame |
|
|
Describe 2 ways to detect errors on the link layer |
Parity bit. Is thr number of 1s even of odd? Easy but unreliable CRC cyclic redundancy check. Result is held in a checksum part of the frame. Calculated by sender and receiver to check same answer. |
|
|
How to mark the start/ end of a frame? |
Use a FLAG byte value to mark it. If a flag occurs in the actual data use and escape byte. And also escape escape bytes in the data and so on. |
|
|
Media Acces protocol |
MAC manages access to and fron the physical medium. It is part of the link layer. Is sends frames to and from physical and manages collisions. Specific to the physical layer |
|
|
CSMA/CD def |
Carrier sense multiple access with collision detection Used by original wired ethernet |
|
|
CSMA CD |
Like a telephone conversation. Sender listens to see if media is busy, when free sender starts to send and will stop if collisions occur. Pause before restarting if a collision does occur. |
|
|
Wifi collision avoidance |
CSMA/CA instead CA is collision avoidance. Instead of listening for clear, waits for an acknowledgement from the ap to determine if the frame was successfully sent. |
|
|
Describe why heterogeneity is an challenge in d.s |
Heterogeneity means there's no one decided way. E.g. different programming languages, different OS. |
|
|
Describe why openness is a challenge in d.s |
Open systems can be extended e.g. adding more computation or storage resources or adding additional services. This can be difficult to achieve |
|
|
Describe why scalability is a challenge in d.s |
Scalable systems can handle a significant increase in either the number of resources or the number of clients. Without loosing too much performance, cost, causing bottle necks, etc. |
|
|
Describe why failure handling is a problem in d.s |
Need to be able to: detect, mask, tolerate, and recover from failures. |
|
|
Describe why transparency is a challenge in d.s |
Let the user perceive the system as a whole instead of broken up? I think? |
|
|
Describe why Quality of Service is a challenge in d.s |
Need to meet deadlines, depends on availability of resources. QoS would guarantee available resources even for high workload |
|
|
What 4 things are the building blocks of a d.s |
The communicating Entities The communication paradigms The roles and responsibilities And the placement (within the physical distributed infrastructure) |
|
|
Partitioning objects over multiple servers vs replicating them |
Partitioning: + fault tolerant, load balancing - need to ensure consistency Replication: + no consistency overhead - no real fault tolerance |
|
|
Describe tiering in d.s |
Splitting functionality into groups/ layers. E.g. client server would have presentation, application, data Presentation- users and view controls Application- Application server Data- database manager |
|
|
Note to self |
I skipped all the pros and cons of different teiring levels. Go back if there's time |
|
|
What are the 3 main use cases for leader elections? |
When each process is roughly the same and thre is no clear permanent leader. When a cluster is performing a complex task with close collaboration When the system has many distributed data writes and requires good consistency |
|
|
List at least 3 advantages of leader elections |
Systems easy for humans to design because concurrency is in single place Reduces partial failure modes Single place for logs and metrics Improve performance costs by providing a single consistent cache if data Efficient because it can inform other systems about changes Efficient because it can inform other systems about changes |
|
|
What are the 3 requirements of a leader election |
Termination- algorithm must stop in finite time once leader selected Uniqueness- only one process considers itself leader Agreement- all processes know who the leader is |
|
|
Define safety in leader elections |
One process is the leader and all others know the leaders identifier |
|
|
Define liveness in leader elections |
All processes participate and eventually are elected to receive leaders identifier |
|
|
What is the main difference in synchronous and async leader elections (- def) |
Sync can guarantee safety and liveness async can not |
|
|
Main steps of ring leader elections |
1) process decides election needed. Makes itself participant. Sends election message left 2)when get election msg, compares msg ID and its own. If msg is greater it forwards it. If msg is less: If it is not participating yet it forwards the msg but with its own ID and participates If it is participating is shallows the msg If the msg ID is its ID it is the leader. Sends elected msg with its ID left and stops participating. 3) receieve elected msg, stop participating, notes the ID. If not its own forwards msg on. |
|
|
What happens in ring leader election if multiple get started at once? |
The participant flag triggers a process stop election messages with lower IDs but election msgs with higher IDs will pass. Aka just one ends up finishing. Worst case N(N-1)/2 additional messages |
|
|
Does ring leader election have saftey? |
Yes. Only the process with highest ID can be selected |
|
|
Does ring leader election have liveness? |
??yes?? Every process participates and receives the elected message Extra elections are stopped |
|
|
What does bully election assume? |
System is synchronous Message delivery is reliable Processes may fail any time But failed processes are detected Each process knows the ID and address of all other processes |
|
|
Main steps in bully election |
1) when process P recovers from failure or the current coordinator fails, p does this: If P has the highest process ID it sends a coordinator msg to all other processes and becomes coordinator Otherwise P broadcasts election msg to all processes with higher ID than it 2) if P receives no Answer msg after sending an election msg then it becomes coordinator 3) if P does receive answer from process with higher ID it just waits to hear the coordinator msg. Restarts process after timeout 4) if P receives election msg from lower ID it sends Answer back. If it has not already started election it starts one. 5) if P receives coordinator msg the sender is the coordinator. |
|
|
Is bully election safe |
Not always! A lower ID process always yields to a higher ID one. But failure of a process may lead to two coordinators... |
|
|
Does bully election have liveness |
Yes! Every process participates and knows the coordinator at the end. Multiple concurrent elections does not change outcome. |
|
|
Application layer multicast is better than network layer multicast because... |
Network layer has small packet size and unreliable, out of order, delivery Application layer is more readily available across range of devices |
|
|
Basic multicast guarantees that |
A correct process will eventually deliver the message IF the multicastor doesn't crash
Only group members receive messages sent to the group. Duh??? |
|
|
Do you remember what the basic multicast diagram looks like? |

Wow so great |
|
|
What does reliable multicast guarantee |
Integrity- a correct orocess delivers a message m at most once Agreement- if a correct process delivers message m then all other correct processes in group with eventually deliver m Validity- if a correct process multicasts m then it will eventually deliver m Therefore all together ensure liveness |
|
|
Reliable muticast steps |
Initialize set received as empty Send a message. All received the message including sender When a message delivered If not already received add to received set Then multicast the message (unless was og sender) Then deliver the message to the receiving process |
|
|
Downside of reliable multicast |
Inefficient. O(N^2) mesagea for every multicast. Not practical for large groups. |
|
|
Describe multicast gossip |
Og sender sends to 3 random processes When anything receives a msg for the first time, forwards it on to 3 random processes High probability of reaching all processes |
|
|
What is ordered multicast |
Tries to establish a delivery order for messages, unlike e.g. reliable multicast. FIFO- if m1 and m2 sent by SAME SENDER whichever is send first must be delivered first Casual- if a multicast happens before another it must be delivered before the other Total order- if m1 is delivered before m2 to a process then m1 must be delivered before m2 to all processes in group. |
|
|
Note to self |
I skipped all the algorithms for the 3 ordered multicasts. Hopefully just vuagely knowing what they are is enough!?!? Do at least learn that if the leader fails in TO multicast the whole thing fails |
|
|
Cristian's algorithm |
Physical clock synchronisation 1 client process requests the time from a clock server 2 clock server responds with time 3 client receives response and calculates the synchronised clock time which is server time plus half round-trip time. |
|
|
Brekeley algorithm assumptions |
Assumes each machine node in network doesn't have an accurate time source of doesn't possess a UTC server |
|
|
Berkeley algorithm steps |
1 an individual node is chosen as the coordinator using a leader election 2 coordinator requests time from each node using Cristian's algorithm 3 coordinator calcualtes adverage time difference 4 adverage time difference is added to the coordinators clock 5 the coordinators current time is Then broadcast over the current network |
|
|
Berkeley algorithm improvements |
1 ignore outliers when averaging 2 if coordinator fails a 2nd leader should have been pre chosen to reduce down time 3 broadcast relative inverse time difference instead of final time to reduce latency in network |
|
|
Overview NTP |
Network time protocol Time sync protocol that runs across Internet uses Stratum level (hierarchy of time servers) 0-15 indicates decices distance to the reference clock E.g. Stratum 0 is high precision devices e.g. atomic clocks, GPS, radio clocks Stratum 1 is attached to a 0 S2 is synced over network to a S1 S3 synced over network to S2... and so on |
|
|
What is a logical clock |
Counts events that occur rather than physical time |
|
|
Describe how Lamport clocks work |
Each node has a counter that increments on every local event When a message is sent the value t is sent with it When a message is received if t is higher than local t, local t is moves forward to relieved t and incremented |
|
|
What orders do Lamport clocks allow |
They can define total order They can define casual order |
|
|
What is a limitation of Lamport clocks |
With two events even if one is lower t than the other you can't tell which happened before, or if they were concurrent |
|
|
Describe vector clocks |
Allow detection of concurrent events Assumes N nodes in system Vector timestamp of a is V(a)=<t1,t2,,,,tn> Where ti is number of events observed by note Ni Nodes increment local timestamp each event And attach timestamp to each message Recipients of messages merge timestamp into their local vectors |
|
|
Define safety in relation to critical regions |
Only one processes is in a CR at a time Freedom from deadlock, at least one process can take an action and enter a CR |
|
|
Define liveness in relation to critical regions |
Every process trying to enter a CR must eventually succeed |
|
|
Define fairness in relation to critical regions |
Access to CR should happen in a fair order e.g. FIFO |
|
|
Mutex centralised algorithm stels |
Process 3 requests token to access CR Token is granted P2 requests token P2 added to coordinators queue P1 requests token P3 releases token P0 grants token to P2, removes P2 from queue |
|
|
Is centralised algorithm safe |
Server ensures grant is only sent after release is received Queue ensures only one process can enter CR So yes! |
|
|
Is centralised algorithm safe |
Server ensures grant is only sent after release is received Queue ensures only one process can enter CR So yes! |
|
|
Is centralises algorithm liveness |
Server maintains queue so all processes eventually gain access So yes! |
|
|
Is centralised algorithm fair |
Server maintains queue so enter CR in order. But can't ensure happened-before ordering if system is asynchronous So yes for synchronous systems |
|
|
Mutex ring token algorithm steps |
P0 has token, its queue is empty P0 releases token to p1 P1 accesses the critical process oldest item in queue Removes oldest item in queue P1 releases token to P2And so on. So if a node needs CR it puts the process in its queue and does it when it gets the token. If it gets the token with an empty queue it just passes it on And so on. So if a node needs CR it puts the process in its queue and does it when it gets the token. If it gets the token with an empty queue it just passes it on And so on. So if a node needs CR it puts the process in its queue and does it when it gets the token. If it gets the token with an empty queue it just passes it on |
|
|
Is mutex ring algorithm safe |
There is only one token so only one can enter CR at a time Deadlock free because one token
So yes! |
|
|
Is mutex ring algorithm liveness |
Every process gets equal access as token passed around
So yes! |
|
|
Is mutex ring algorithm fair |
Not fair as order is based on ring and location of token when starting |
|
|
Raymond's tree based algorithm steps |
Each node has one parent. Child can only send requests to parent. Each node has a FIFO queue of requests. If a node- n, is not holding the token wants CR it passes a request to its parent- j If the Js queue is empty it moves the child- n- into its queue then sends a request to its parent- k, for the token If Js queue is not empty just adds the child- n, to the queue When K, that has the token, receives a request it sends the token to J and sets J as its parent When J receives the token it forwards the token to n, J must issue a request to n to get the token back The swapping basically means the node with the token is always the root of the tree. |
|
|
Is Raymond's tree algorithm safe |
Only one process can hold the token Deadlock impossible So yes! |
|
|
Is Raymond's tree liveness |
Algorithm can cause starvation as it uses a greedy strategy where a site can execute the CR when getting a token even if its request is not the top of the queue So no! |
|
|
Is Raymond's tree liveness |
Algorithm can cause starvation as it uses a greedy strategy where a site can execute the CR when getting a token even if its request is not the top of the queue So no! |
|
|
Is Raymond's tree fair |
Everyone is allowed to hold the token, non greedy strategy Is what notes said but I thought it was greedy?!?? We will just say yes because idk |
|
|
Ricart Agrawala algorithm steps |
Site is any device running the algorithm All sites have a queue Request msg contains ID and timestamp When a site wants CR It broadcasts to all other sites All sites add it to their queue+ respond IF - it itself is not currently wanting the CR - it itself is lower priority based on time Otherwise they will just respond Requesting site waits for all responses to be positive and then uses CR When done with CR sends any deferred response messages ifself If this doesn't make sense the slides do! |
|
|
Is ricart agrawala safe |
If a process is in CR it can't respond until it leaves and processes can't join until getting all responses. Lowest timestamp always goes first So yes! |
|
|
Is ricart agwala liveness |
Total ordering of timestamps ensures each request will eventually get all replies So yes! |
|
|
Is ricart agrawala fair |
Clocks ensure fair ordering So yes! |
|
|
What are the three token based mutual exclusion algorithms? |
Centralised Ring Raymond's |
|
|
What are the two non token based mutex algorithms |
Lamport's Ricart Agrawala |
|
|
What is the Quorum based mutex algorithm |
Maekawa's |
|
|
Maekawa's algorithm steps |
Please just go over this it's too much to write on a flashcard |
|
|
Maekawa's safety |
Processes can only vote for one other at a time so only one process can get enough votes to enter CR |
|
|
Maekawa's liveness |
Very easy to deadlock E.g. 2 send request at same time So no! |
|
|
Maekawa's fairness |
No! But can be introduced using vector clocks to determine the order of requests |
|
|
What is a consensus algorithm |
A process to achieve agreement on a single value among distributed processes |
|
|
In byzantine generals how many malicious parties can be tolerated |
Less than a third. Aka for N malicious generals must have 3N+1 total |
|
|
What are the required results of a consensus algorithm |
All correct processes must correctly set their value and have decided on the same value |
|
|
Describe solving consensus with total order multicast |
all N processes TOmulticast their proposed value Then for example all processes could then just take the first delivered by TOmulticast This is because TO guarantees all processes see messages in the same order! This also works the other way around so a solved consensus algorithm could be used to implement TO by consensusly deciding the next message each time. |
|
|
Describe how a consensus algorithm can tolerate crash failures |
Assume basic multicast guarantees delivery of messages to correct processes Works in rounds with a timeout each time to detect failure Round 1: deliver proposed value, store all received values that round. Subsequent rounds: only deliver a value from the previous round, save that rounds, and repeat Final round: choose value based on selection criteria. (I assume like, pick highest?) For F crashes you need at least F+2 processes and F+1 rounds |
|
|
Consensus in asynchronous systems |
Can't detect crashed processes Can't use timeout to detect missing msg Can not guarantee consensus, only to a certain probability of reaching one |
|
|
Primary backup replication steps |
It's almost exactly how the cw works
It's almost exactly how the cw worksExcept responses to requests are stored so that if a request comes on that's already been executed it doesn't execute again and just sends the response
Also primary is a data store itself chosen by leader election |
|
|
Describe CAP theorem |
Consistency- all replicas of a data object are always in the same state Availability- requests are served as long as at least one server is available Partition tolerance- data store keeps working even if servers are partitioned CAP theorem says it is impossible to achieve all three, at most 2 can be had |
|
|
CAP- AP systems |
Can't have true consistency but can have eventual consistency! This is done with a partially synchronous system. In synchronous periods servers reconcile data objects and replicas to make consistent. In asynchronous periods read operations may not give up to date data Eventually data will be consistent. |
|
|
CAP- AP systems |
Can't have true consistency but can have eventual consistency! This is done with a partially synchronous system. In synchronous periods servers reconcile data objects and replicas to make consistent. In asynchronous periods read operations may not give up to date data Eventually data will be consistent. |
|
|
CAP- CA systems |
These don't have partition tolerance so assume partitions can't happen. But that's kind of impossible as network partitions can ways happen. So CA systems aren't really an option |
|
|
Scalability quick notes |
Can be measured in different ways, throughput, latency, availability There is a point where adding servers stops improving throughput. |
|
|
Describe strong consistency models |
Used by CP approaches Requires global ordering of updates When updates are committed replicas need to reach agreement on global ordering |
|
|
Describe weak consistency models |
Used by AP systems No global ordering More relaxed guarantees on consistency- I.e. eventually consistent |
|
|
Describe passive replication |
One replica is considered primary Clients communicate with primary Any others are backups If primary fails backups take over Leader election picks new primary |
|
|
Describe active replication |
Clients communicate with group of services (replicas) When a client writes to a replica the update is propagated to a with TOmulticast |
|
|
Strict consistency model |
Any write update is IMMIDIATELY available to read. Like the system is a single store Impossible on distributed systems as requires instant messaging. |
|
|
Linearizability consistency model |

Slightly weaker version of strict consistency Individual opperations weaved into a single TO that respects the local ordering of every process If opperations overlap they can be up to date or not and it's still fine |
|
|
Sequential consistency |

Weaker version of strict and linearizability Doesn't care about timing just program order Sends write updates to all with TOmulti Doent need synced clocks If write x to b happens before another write x to a then nothing reading x will read a before b |
|
|
Casual consistency |
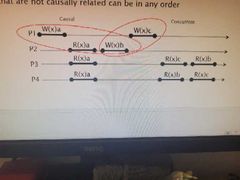
All writes that have a causal relationship must be seen by every process in the same order. Orders of values returned must match the casual order. Unrelated writes can be in any order Uses vector timestamps. Updates writes with multicast and timestamp, doesn't need synced clocks. Ngl idk what this means |
|
|
Eventual consistency |
No guarantee for how long consistency will take, just eventually. But an application must be able to tolerate the lack of consistency Also conflicts may occur so requires a way to solve that e.g. global consensus on answer, roll back, or delegate to application |
|
|
Strong eventual consistency |
Addresses weakness of eventual consistency Adds that if any two replicas have received the same set of updates in any order they will be in the same state Does not require waiting for network communication. Can use casual multicast for updates Use CRDT to manage concurrent updates |
|
|
Two types of CRDT conflict free replicated data type |
Operation based CRDTs On write only broadcasts opperation On recieve broadcast apply operation Often used in collaborative editors
State based CRDTs On write broadcast full state On receive broadcast merge states E.g. grow only counter |
|
|
Quorum replication |
Quorum is a subset of replicas dynamically selected during opperations Clients read from a read quorum and write to a write quorum The quorums of both types intersect to insure consistency |
|
|
Note to self |
Skipped notes on peer to peer. I think it's mostly guessable haha |
|
|
Request reply protocol fails on: |
Process crashes Channel omission failures Message out of order |
|
|
Request vs request reply vs request reply acknowledge |
R alone has no safety e.g. lost messages are undetected RR detects issues like server crash, lost msgs, using timeouts. But reply history (if exists) will grow unbounded. RRA does all the above and also but reply history can be kept shorter by discarding replies that have been acknowledged |
|
|
Request vs request reply vs request reply acknowledge |
R alone has no safety e.g. lost messages are undetected RR detects issues like server crash, lost msgs, using timeouts. But reply history (if exists) will grow unbounded. RRA does all the above and also but reply history can be kept shorter by discarding replies that have been acknowledged |
|
|
RPC remote procedure call definition |
Provides high level communication paradigm used in OS. Assumes lower level exists e.g TCPIP or UDP Used to implement client server systems |
|
|
RPC aim |
To make remote prcedure calls as much like local procedure calls as possible. There should be no difference in syntax.
Only differences are stuff like failure rate, latency, call by reference unsupported |
|
|
RPC call semantics |
Maybe- no fault tolerance At least once- retransmit request messages At most once- above but also filter duplicates and retransmit replies |
|
|
Interface defention lanagues |
Describes a RPC interface in a langue specific way. Enables communication between software components e.g. in different languages Defines structures and types One example is Sun RPC which uses UDP and at least once semantics |
|
|
RMI remote method invocation. |
The object oriented equivalent of RPC Client calls a method on a remote object as if it were local Uses interfaces built on request reply protocols. |
|
|
RMI garbage collection |
If the lang has garbage collection then the distributed object needs to coordinate with it. Therefore a module implementing distributed garbage collection is needed This is usually based on reference counting |
|
|
Reference counting |
Used for distributed garbage collection When a remote object ref is created and sent the ref count is incremented When the remote ref is no longer needed by the remote process the ref count is decremented. |
|
|
Note to self |
I skipped the section on Java RMI... |
|
|
Define a transaction |
a set of related sequential operations that is guaranteed by the server to be atomic in the presence of multiple clients and server crashes. |
|
|
ACID properties |
Properties if database transactions intended to guarantee data validity Atomicity- transactions are all of nothing Consistency Isolation- transactions don't interfere with eachother Durability- transactions effects are saved permanently |
|
|
Transactions crash recovery |
Objects must be recoverable. This is to support transaction durability and atomicity after a crash. |
|
|
Transaction concurrency |
Synchronisation of opperations in different transactions is necessary to support isolation. Concurrent execution of transactions is allowed if it produces the same effect as if they were done serial. Aka they ate serially equivalent |
|
|
Lost update problem |
When working concurrently can be issues e.g. setting a value to the read+100 but in between the read and update a different process changed the value. Now whatever that different process did is essentially lost. Good in slides! |
|
|
Inconsistent retrievals problem |
Reads happening around writes are inconsistent if happen one side of the other of the write. Not entirely sure on this one tbh |
|
|
When do operations conflict |
If their combined result depends on the order they are executed. E.g. Read and write conflict but two reads dont |
|
|
How to tell if something is serially equivalent |
Find the conflicting operations! E.g. Read and write of the same object. For each group, for each opperation in the group note which process came first. For them to be serially equivalent the same process must always be first. |
|
|
Concurrency controls- locks |
Before object is accessed it is locked. Only the transaction it is locked for can access it now. Lock is removed when transaction completes. Can cause deadlocks Maintains consistency |
|
|
Concurrency controls- optimistic CC |
Assumes conflicts between concurrent transactions are infrequent Read- each data item read is associated with a timestamp or version num Validation- transactions recheck data items. Compare recorded timestamp and current ones. If all match proceed if not roll back Write- data items are written to and get new timestamp or version |
|
|
Premature writes |
Multiple transactions try to write to one thing
One succeeds but then is aborted
Object is left in an inconsistent state |